はじめに
AIの活用はさまざまな場面に広がってきており、AIが私たちの生活をより豊かにすることが期待されています。しかし、AIチャットボットが差別的な発言を繰り返してサービスが停止されるケースなど、AIの問題点が顕在化する場面も散見されます。このような問題点に対処するために、AIガバナンスに関する議論が世界各国でなされています。
AIがもたらす可能性のある危険性を抑止するために、AIの開発者や利用者が守るべき原則として定められる「AI原則」についてはコンセンサスが得られつつありますが、“AI原則を具体的にどのように実践していけばよいか”という点は、依然として不明確な状況と考えられます。
本稿では、AI原則をより一歩進めた「AIガバナンスの実践のための指針」を示すべく、前回の前編では、「AIガバナンスの問題点」「海外での議論の状況」「AIガバナンスに関するアプローチ」などを整理しましたが、後編の今回は、まず、前編の最後に提示した具体的なAI活用事例をもとに、当該事例の実施可否等を検討します。その検討を踏まえて、どのような事項を検討する必要があるか、および、具体的にどのようなガバナンス体制を実践していく必要があるかという点を検討します。
事例の検討
前編で示した事例は以下のとおりです。
【事例】
A社は、各企業の情報など就活に役立つ情報提供を行うポータルサイトを運営し、就活生が当該ポータルサイトで
・ どのような経路で
・ どのような情報を
・ どの程度
見ているかというようなポータルサイト上の“行動履歴データ”を保有している。この行動履歴データと、過去の内定辞退者の行動履歴データとをAIで分析することで、内定辞退率をスコアリングすることとした。当該内定辞退率は、契約した企業に就活生の氏名とともに提供するサービスを提供することとした。
【設問】
あなたがA社のAIガバナンス担当者であると仮定して、上記事例をどのように判断するか(A社は個人情報保護法で求められる対応は実施することは前提とする。)。
設問① 本プロジェクトの実施は可能と判断するか。
設問②-A ①で「可能ではない」と判断する場合、どのように社内で説明するか。
設問②-B ①で「可能である」と判断する場合、どのようなガバナンス体制の構築や対応を行うか。
本事例では、個人情報保護法で求められる対応は実施していることが前提となっています注1)が、法令上問題がなければ本プロジェクトは実施してもよいのでしょうか注2)。各設問について、以下で検討していきましょう。
本事例における具体的検討
設問① 本プロジェクトは実施可能か?
プロジェクト実施の可否を判断するにあたっては、さまざまな事項を検討する必要があります。ここでは、
・ AI利活用の目的の適切性
・ 分析するデータ項目の合理性
・ 侵害される利益(被侵害利益)は何か
・ データ主体の理解はどうか(事業者の理解とのギャップの有無)
について、以下の(1)~(4)においてそれぞれ本事例にあてはめて検討してみます。
なお、上記の項目は検討事項のすべてではありませんが、AIガバナンスにおいて重要なものです。その理由については、主に下記Ⅳ(AIガバナンスにおける検討フレームの整理)で解説します。
(1) AI利活用の目的の適切性
まず、本事例におけるAI利活用の目的が適切なものかを検証します。
本事例におけるAI利活用の目的は、就活生の内定辞退率をスコアリングし、契約した企業に提供することです。採用を行っている企業としては、採用活動にお金・時間をかけて見つけた優秀な人材に対して“内定辞退はせずに入社してほしい”と考えることは自然なことですから、こうしたデータの提供に価値があると考える可能性は高いといえます。
他方で、就活生からすると、内定辞退率を推定されることには強い抵抗感があるのではないでしょうか。この背景には、“内定辞退率が推定されてしまうことで、選考過程に影響が出うるのではないか”という危惧があると思われます。仮に、「推定された内定辞退率は選考過程では使用せず、選考過程後の内定辞退を回避するためのフォローアップに利用する」ということが契約上義務づけられていたとしても、この危惧は依然として残り続けるように思います。
個人情報保護委員会が公表した資料注3)によると、採用活動にかかわる情報は「学生等の人生をも左右しうる」ことが指摘されており、特に重要な権利利益が対象となっています。そのような人生に大きな影響をもたらしうる自身の決断の背景を、第三者に勝手に覗き見されるようなことには強い抵抗があると考えられます。
そのため、そのような内定辞退率をスコアリングし、契約した企業に提供するという目的自体、“適切ではない”と判断すべきものといえるのではないでしょうか。
(2) 分析するデータ項目の合理性
次に、“AIがどのようなデータ項目を分析するのか”という点や、その合理性についても検討します。
本事例を検討すると、就活生が重視している情報や、反対に重視していない情報を行動履歴データから読み取ることで、過去の内定辞退者の傾向との類似の程度は一定程度判定可能と思われます。仮に、過去の内定辞退者が重視していた項目と、当該就活生が重視していた項目とが一致する場合に“当該企業とこの就活生はマッチしない”と考え、“内定辞退する可能性がある”という評価に至ることは合理性があるといえるでしょう。
そのため、内定辞退率の推定のために、当該就活生がどのような情報を閲覧しているかという行動履歴データを用いることは関連性があり、合理的であると考える余地があるように思います注4)。
(3) 侵害される利益(被侵害利益)は何か
次に、“本事例において、どのような利益が侵害されうるのか”を検討します。ここでは、侵害されうる利益の①性質と②程度を検証します。
①については、AIプロファイリングの場合、侵害される利益(被侵害利益)として一般的に問題とされるのはプライバシー権ですが、本事例においては、さらにAIプロファイリングの活用の場が“企業の採用活動”であることから、プライバシー権に加えて職業選択の自由についても問題となり得ます。本事例においては、職業選択の自由の中でも、“最初にどの企業に入社するか”に関する就活生の考え方が含まれており、この情報は特に「学生等の人生をも左右しうる」ことから、特に重要な権利利益と考えられます。
②については、仮に、あまり重要ではないと考えられる利益が侵害されうる場面であっても、侵害の程度が大きい場合には、十分な規制が必要になり得ます。
AIが出力したアウトプットがそのまま何らかの法律効果に結びつくような場合には、侵害の程度が大きくなる可能性があります。たとえば、“日々の行動からその人がどの程度信用できるかを数値化した信用スコアが一定以上でないと一定水準以上の家が借りられない”ということになる場合、AIのアウトプットによって、“その家が借りられるか借りられないか”という問題につながることになります。他方、AIのアウトプットは人の意思決定の参考になるにとどまるという程度であれば、人に与える影響の度合いは低いと考えられます注5)。
本事例についてみると、AIが推定した内定辞退率が直接就活生の採用の合否に影響する場合には、就活生の権利利益に大きな侵害をもたらすものと考えられます。他方、内定辞退率が直接合否に影響するものではなく、企業の担当者が内定辞退率を参考に、内定辞退をしないようフォローを行う場合は、人間の判断の参考にとどまると考えられるため、就活生の権利利益の侵害は一定程度にとどまると考えられることが可能です。
以上をまとめると、本件における被侵害利益の性質(①)は、プライバシー権と職業選択の自由と、重要な権利といえます。また、侵害の程度(②)は、実際の使われ方によりますが、“就職に結びつく”という意味で、一定程度の侵害があると考えられます。
(4) データ主体の理解はどうか(事業者の理解とのギャップの有無)
上記(1)~(3)と視点は異なりますが、“データ主体がどのように想定するか”という主観面についても検討しなければなりません。
一般的に、事業者側が設定するデータの利活用の範囲は、データ主体が想定するデータ利活用範囲よりも広くなります。この両者の範囲が大きく異なる場合に炎上に至る可能性が高まると考えられます(図表1)。そのため、両者の範囲が大きく異なることが想定される場合には、データ主体に対して事前に十分かつわかりやすい説明を行うことが必要です。
図表1 事業者側が設定するデータ利活用の範囲と、データ主体が想定するデータ利活用の範囲の関係性
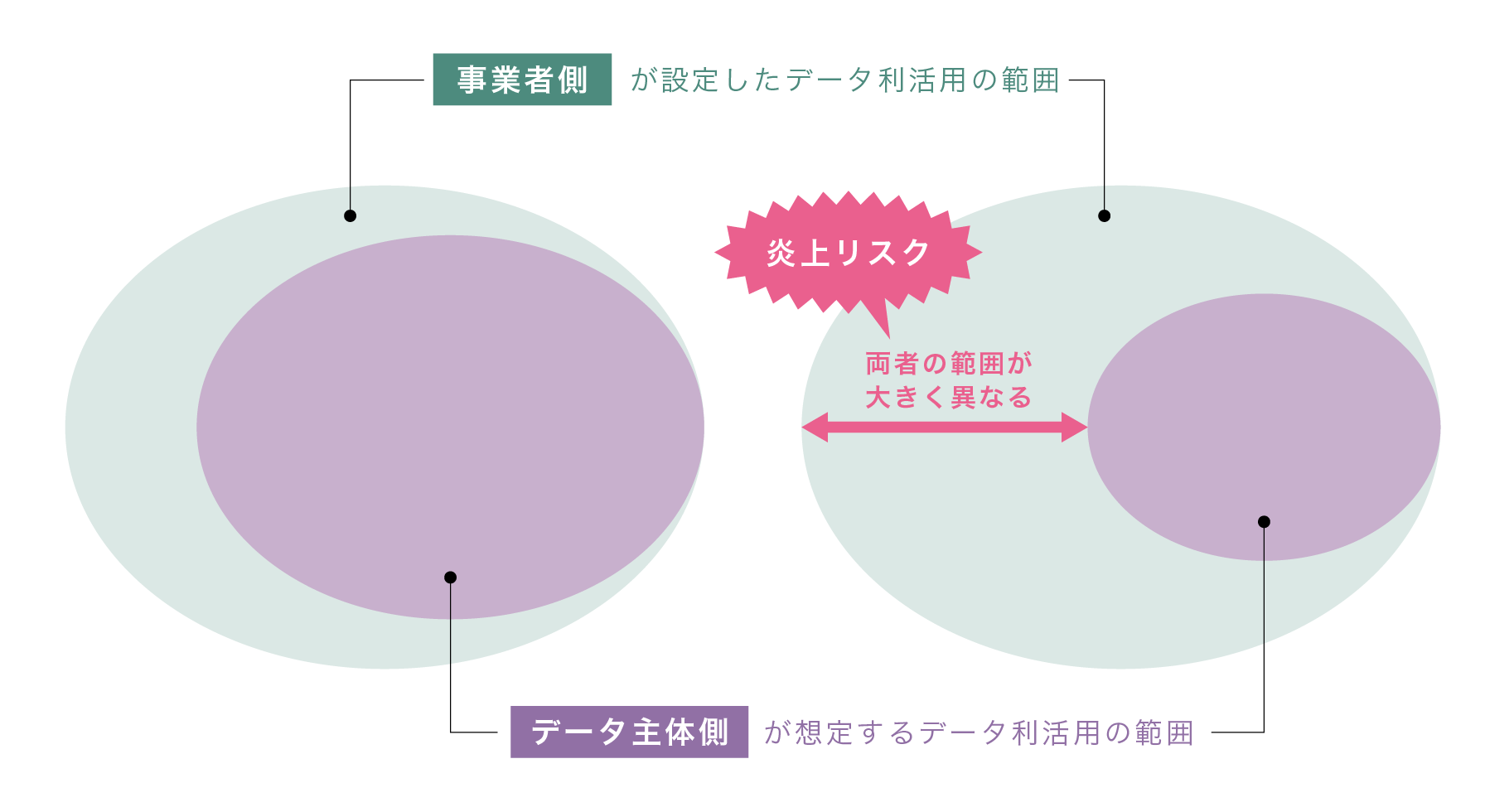
本事例では、データ主体である就活生は企業情報を得るために会員登録を行っていたと考えられ、行動履歴データから内定辞退率をプロファイリングされることまで想定することは困難といえるでしょう注6)。
また、内定辞退率の推定は、就活生にとっては非常にセンシティブな結果をもたらしうるプロファイリングです。そのため、仮に企業側が説明を十分に行ったとしても、大多数のユーザー(データ主体)はそのような使い方を許容しない(同意しない)のではないでしょうか。プライバシーポリシーなどでの利用方法の説明があったとしても、“任意に同意が得られていたのか”という議論が生じ得ます注7)。
このように、本件においては企業側の利用範囲(内定辞退率の推定)とユーザーが想定する利用範囲(企業情報の閲覧)は大きく異なるといえます。
(5) 設問①の結論—実施可能と判断するか
(4)までの検討結果を整理すると、図表2のとおりになります。
図表2 本事例の検討結果
|
項目 |
検討結果 |
|
AI利活用の目的の適切性 |
就活生の内定辞退率をスコアリングすることは不適切である。 |
|
分析するデータ項目の合理性 |
行動履歴データを用いることは、内定辞退率スコアリングには合理性がある。 |
|
被侵害利益は何か |
プライバシー権に加えて、職業選択の利益を含む重大な権利を侵害しうる。 |
|
データ主体の理解はどうか |
企業の利用範囲とデータ主体が想定する利用範囲とは大きく異なる。 |
上述のとおり、本件では、“目的が適切ではない”と考えられます。そのため、設問①の結論としては、“実施可能ではない”と判断することになると考えられます。
なお、本来、目的が適切ではない場合、どのような方法であっても実施すべきではないという結論になるため、理論上は残る3項目(上記(2)~(4))のような検討は不要となります。しかし、“目的が適切ではない”とはっきり言い切れる事案は少ないと考えられ、また、目的を変えた場合には実施が可能となる余地があるため、4項目すべてについて検討しておくことが望ましいといえます。
設問②-A(社内における説明)
(1) 社内でどのように説明するか
“可能ではない”という結論の場合、“社内でどのように説明するか”も非常に重要なポイントとなります。
基本的には設問①における検討結果を社内で伝えるのがよいと考えられますが、その際、実際に炎上などが問題になった類似事案と併せて説明することで、より説得的な内容になるのではないかと思われます。
(2) 実施可能性の検討
上記⒈で検討したように、設問①での結論は“実施可能ではない”となりましたが、どうすれば実施することができたのでしょうか。そもそも、本プロジェクトは実施困難なものなのでしょうか。ここでは、“プロジェクトの内容を変えることで実施できないか”を検討したいと思います。
“目的が適切かどうか”という検証においては、“目的をつまびらかに公開することができるか”が一つのポイントになると思われます。ユーザーに対して隠したい部分がある場合は、“目的が適切ではないのではないか”という推測が働くこととなります。
本事案では、“内定辞退率を推定する”という行為についてつまびらかに公開することは難しかったのではないでしょうか。これは、当該行為がデータ主体の利益につながらないことも一因であると考えられます。仮に、“就活生の閲覧履歴などを分析し、その就活生に対し、企業ごとにマッチ度を推定する”といった行為であれば、推定・提供される情報はデータ主体にも有益なものとなるため、目的のつまびらかな公開も特段の問題はなく、また、データ主体も同意する可能性が高いのではないでしょうか注8)。
本事案が“内定辞退率を契約企業に提供する”というスキームである限り、仮にプロジェクトの内容を変えたとしても、実施は困難という結論にならざるを得ないのではないかと思われます。
(3) 小括
以上は、あくまでも大枠について議論をしているため、本来は、具体的な事実関係をもとにより多くの事項について詳細に検討することが不可欠です。
また、プロジェクトの実施にあたって想定されるさまざまな事案を検討した結果を踏まえたガバナンス体制を構築することも必要となります。本事例の検討から明らかとなったポイントは、以下のとおりです。
・ 職業選択の自由を侵害しうるようなAIプロファイリングについては、より慎重な対応が求められる。
・ プロジェクトの目的が適切であるかどうかの検証は特に厳密に行う必要がある。
AIガバナンスにおける検討フレームの整理
Ⅲにおいては、本事例について四つの視点での検討を行いました。以下では、AIガバナンスとしてどのような検討を行うべきか、特に本事例で検討を行った四つの視点がなぜ重要となるのかについて整理を行います。
原理原則アプローチがなぜ必要になるのか
前編で説明したとおり、AIガバナンスにおいては、想定されるリスクに応じて、規制や対応の程度を変動させることが望ましいとされます(リスクベースアプローチ)。そのため、“どのようなリスクがあるか”“そのリスクはどの程度か”という検討が出発点となります。この検討において、原理原則アプローチが指針となります。
AIにおいて尊重すべき原理原則としてAI原則があります。改めてAI原則を見てみると、
① 包括な成長、持続可能な開発および幸福
② 人間中心の価値観および公平性
という実体的な内容と、
③ 透明性および説明可能性
④ 頑健性、セキュリティおよび安全性
⑤ アカウンタビリティ
という手続的な内容に分けることができます注9)。
侵害される利益(被侵害利益)
⒈で紹介したもののうち、②人間中心の価値観および公平性においては、個々人に対する影響・侵害される利益(被侵害利益)が重要なポイントとなります。具体的には、Ⅲ⒉(3)で行ったように、“AI利用によってどのような権利利益が侵害されるおそれがあるか”という検討を行う必要があります(Ⅲ⒉(3)での本事例の検討においては、プライバシー権に加えて、職業選択の自由といった重要な権利利益が侵害の対象となりました)注10)。
データ項目と目的の合理性・適切性
被侵害利益との関係では、“どのようなデータ項目が使われているか”の検討も必要です(分析するデータ項目の合理性。上記Ⅲ⒉(2)も参照)注11)。これは、差別的な結果をもたらしやすいデータ項目が使われる場合、AIのアウトプットも差別的なアウトプットとなりやすく、権利利益を侵害する結果をもたらす可能性があるからです。
他方、データ項目自体はそのような差別的なアウトプットにつながるとはいえないものであっても、利用目的との関係で、関係性が弱いものを利用することは問題となることがあります。そのため、“データの取扱いが必要となるかどうか”の判断のために、目的を確認する必要があります(AI利活用の目的。上記Ⅲ⒉(1)も参照)注12)。
AIガバナンスにおける手続面の整理(説明に基づく同意とHuman Oversight)
では、主に“リスクがどの程度あるのか”について検討しましたが、リスクベースアプローチでは“リスクに応じた対応”を行う必要があります。以下では“どのような対応を行うべきか”という手続面の検討を行います。
十分な説明と同意
手続面としては、まず“十分な説明を行ったうえで同意を得る”ということが重要となります注13)。この点は個人情報を取り扱うプロジェクトでの検討と共通する内容となります。
これは、Ⅲ⒉(4)で述べたとおり、法令を遵守していたとしてもデータを取り扱うプロジェクトが炎上する主な理由として、データ主体が想定するデータの利用範囲と、企業側が行うデータ利活用の範囲とが大きく乖離している場合があるからです。このような炎上を回避するためにも、十分な説明を行い、データ主体にデータ利活用の範囲を正しく認識してもらうことが重要となります。
また、AIは結論に至る過程が不透明であることに起因して生じるリスクがあります。そのため、AI原則においても、尊重すべきものとしてⅣ⒈で掲げたように「③透明性および説明可能性」を掲げており、ユーザーなどに対する十分な説明が重要とされています。
もちろん、高リスクの場合にはより丁寧でわかりやすい説明を尽くす必要がありますが、低リスクなAI利用であっても、“低リスクだから”と説明を省略するのではなく、AIを利用していることの明示や説明が求められると考えられます注14)。
Human Oversight
さらに、AIガバナンス固有の視点として、AIのアウトプットに対して、“人がどこまで監視するか(Human Oversight)”というものがあります。これは、AIアウトプットの結果が必ずしも想定された範囲内にとどまらない可能性があるため、“必要に応じて人間が監督すべきである”という考えに基づくものです。
本来、AIは人間の関与がなくとも自律的にアウトプットを出せるというところに大きな特徴があるところ、それに反して、人間がAIのアウトプットに対してどこまで関与(監督)する必要があるのかという点を検討する必要があります。一般論としては、よりリスクの高いAI利用については人の監視を強め、よりリスクの低いAI利用については人の監視を弱めることになると考えられます。
この点、EUのAI規則案(Artificial Intelligence Act案(2023年6月14日欧州議会承認版))では、ハイリスクAIシステムにおいて、人間による監視(Human oversight)を義務づけており(14条)、また、市場にAIシステムをリリースした以降については別途モニタリングすべきことを義務づけています(Post Market Monitoring。61条)。
シンガポールでも同様にリスクの程度に応じて人間の関与することを求めています注15)が、EUとシンガポールでの議論は、“リスク分類”と“それに応じてどの程度関与すべきか”という点が必ずしも整合していません。
私見ではありますが、リスク分類においては、リスクの“大きさ”と“発生可能性”という二つの軸によりリスクの大きさを把握するという一般的な整理を示している(図表3)シンガポールをベースとし、そのうえで、具体的にハイリスクとなるAIシステムの特定を試みるAI規則案を参考とするのがよいと考えられます。
図表3 シンガポールのAIフレームワークによるリスク分類
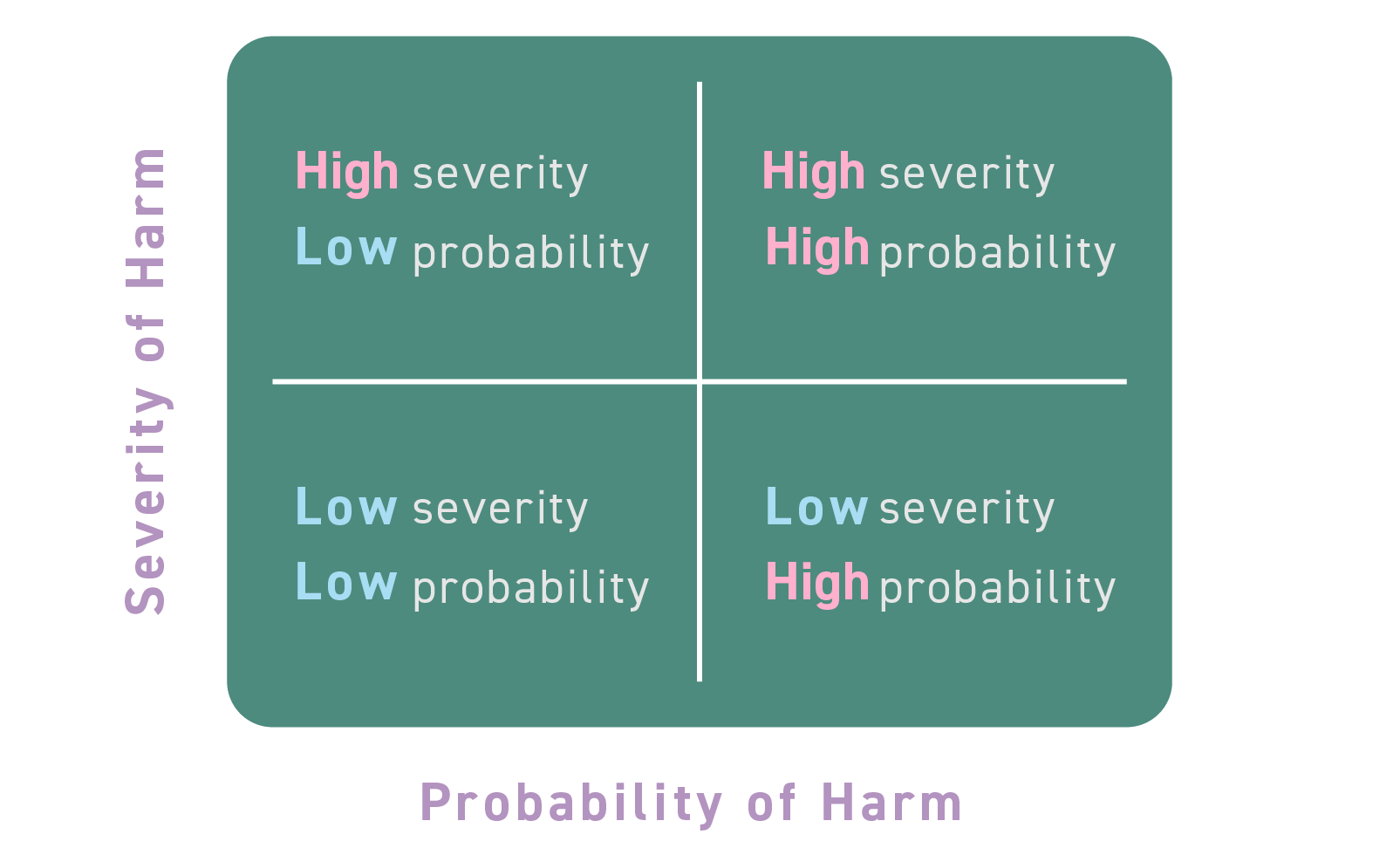
出典:シンガポール個人データ保護委員会“MODEL ARTIFICIAL INTELLIGENCE GOVERNANCE FRAMEWORK SECOND EDITION”31頁を基に作成。
“人間がどの程度関与すべきか”については、
・ 人間がAIアウトプットを承認しなければならないもの
・ 人間がAIアウトプットを監視・監督しなければならないもの
・ 人間が関与する必要はないもの
という大きく三つのアプローチに分かれるものと思われます。さらに、リスクの性質に応じて、人間による監視をどのような内容とするかが現実的に検討されることになります(図表4)。
図表4 人間の関与の程度に関する整理

AIガバナンスとして具体的に何を行うべきか
では、AIガバナンスとしてどのような内容を構築すべきでしょうか。具体的には、①誰が、②どのような事項を、③いつ、判断するのかということを明らかにする必要があると考えられます。
判断の主体(誰が)
判断の主体については、“法務担当者が判断するのか”“一定程度は事業部側で判断してもらうのか”などが考えられます。また、海外子会社がAI利活用を行う場合には、“本社側で判断するのか”、それとも“子会社側で判断するのか”という点も検討する必要があります。
このように“誰が判断するのか”という点については、部署の権限分配に関するものであり、一般的には社内規程に相当するものと考えられます。そのため、まずは社内規程おいて、誰が判断するのかを明確にする必要があるでしょう。
判断事項(どのような事項を)
AI利活用プロジェクトを実施するためには、“何を検討すべきか”を整理した検討フレームを準備しておくことが必要です。
これは、Ⅲ⒉における本事例の検討が参考になります。Ⅲ⒉では“AI利活用の目的の適切性”“分析するデータ項目の合理性”“侵害される利益は何か”“データ主体の理解はどうか”の4項目について検討しましたが、他にも検討すべき事項があると思われます。具体的なプロジェクトの内容を踏まえて判断事項を充実させることが望ましいです。
判断のタイミング(いつ)
⒈および⒉で検討したとおり、“誰が判断すべきか”という社内規定を構築し、判断権者が判断するためのフレームを構築する際に、“いつ判断するのか”という点も明らかにしておく必要があります。具体的には、AIの開発段階で議論すべき内容とAIの利活用段階で議論すべき内容は異なるため、①企画段階・開発段階と②運用段階とに分け、各段階での判断権者と併せて社内規程で明確化していくことが望ましいと考えられます。
このように、AIガバナンスにあたっては社内規程や検討フレームを準備する必要がありますが、その後の社会情勢や他のプロジェクトの動向なども加味して継続的にアップデートしていくことが求められます。
おわりに
AIはさまざまな可能性を示しており、執筆の途中でもChatGPTが非常に大きな話題を呼びました。本稿はAIを利用する場面でのガバナンスを中心に説明しましたが、開発の段階でも留意すべき事項はあります。さらに、生成系AIにおいては、著作権に関する整理も重要となっています。これらの視点についても、ガバナンス体制に含める必要がありますが、この点はまた別の機会に説明することとしたいと思います。
本稿が、不透明なガバナンス体制をより明確にし、多くの企業がAIを活用していく一助となれば幸いです。
- 想定される個人情報保護法上の対応としては、利用目的の特定・公表、第三者提供に関する同意取得などがあります。[↩]
- 本事例は、リクナビDMPフォローを参考にしています。当該事案では法令違反が多数指摘されています(参考:個人情報保護委員会「個人情報の保護に関する法律に基づく行政上の対応について」(令和元年12月4日))が、仮に法令違反がない場合であっても、さまざまな検討が必要となりうる事案と考えられます。なお、事案については、リクルート社のサイト(「『リクナビDMPフォロー』に関するお詫びとご説明」)をご参照ください。[↩]
- 個人情報保護委員会「個人情報の保護に関する法律第42条第1項の規定に基づく勧告等について」(令和元年8月26日)。[↩]
- 他方で、仮に、履歴書の顔写真や、出身大学などを利用する場合は、当該企業の内定辞率と関係はないのではないかという疑問を持たれる方も多いのではないでしょうか。[↩]
- シンガポール個人データ保護委員会“MODEL ARTIFICIAL INTELLIGENCE GOVERNANCE FRAMEWORK SECOND EDITION”32頁等参照。[↩]
- 利用目的の特定(個人情報保護法17条1項)のためには、プロファイリングを行う場合、分析結果をどのような目的で利用するかのみならず、分析処理を行うことも特定する必要があります(個人情報保護委員会「「個人情報の保護に関する法律についてのガイドライン」に関するQ&A」Q2-1参照)。しかし、プロファイリングを行うことを含めて利用目的が特定されていたとしても、ユーザーが十分にプライバシーポリシーを読んでいるとは限らないため、なお、データ主体の認識との乖離の可能性がある点には留意が必要です。[↩]
- 現時点において、個人情報保護法では同意の任意性を真正面から議論していないようです。しかし、GDPRでは、同意が任意になされることを確保するよう求めており(7条4項など)、日本法でもどのような同意が適切かという議論を呼び起こした事案も見受けられました(下記注12、注13を参照)。[↩]
- なお、“企業とのマッチ度”ではなく、ここでも内定辞退率を推定し、“おすすめしない企業”を就活生に示す場合はどうでしょうか。内定辞退率を推定されること自体に反対する考え方も、賛成する考え方もありうるところと思われます。このように、その推定をすること自体が適切ではないと場合と、推定自体は問題ないものの、その結果の“使い方”に問題がある場合とがあります。具体的な事例においては、この区別を意識したうえで検討することが望ましいです。[↩]
- AI原則についての詳細は、経済産業省「我が国のAIガバナンスの在り方 ver1.1」(2021年7月9日)や統合イノベーション戦略推進会議決定「人間中心の AI 社会原則」(平成31年3月29日)等をご参照ください。[↩]
- なお、この検討における権利利益の重要度や、権利利益同士が衝突する場面などの調整については、憲法上の議論が参考となります。[↩]
- 個人情報保護法が保護の目的とする「個人の権利利益」の中核的要素は、“個人データの処理による個人に対する評価・決定の適切性確保である”と指摘し、“個人データは、評価の目的に「関連する」情報のみから構成されなければならない”との指摘があります(GLOCOM六本木会議「デジタル社会を駆動する『個人データ保護法制』にむけて」(2022年12月))。このような観点からも、どのようなデータ項目が使われており、目的との関係に関連しているかを検討する必要があります。[↩]
- なお、“目的が適切でない場合、有効な同意が得られないのではないか”という議論があります。たとえば、リクナビ事件を受け、厚生労働省職業安定局長から全国求人情報協会理事長宛てに出された文書(令和元年9月6日職発0906第3号「募集情報等提供事業等の適正な運営について」)において、「同意を余儀なくされた状態」についても、同意がない場合と同様に、問題があることが示されています。[↩]
- なお、近時では同意に対するさまざまな議論が行われています。“ユーザーがプライバシーポリシーや利用規約を十分読んだうえで意思決定することはフィクションとしても維持できないのではないか”といった指摘や、そもそもプライバシー権を自己情報コントロール権から整理することへの批判などがあります。さらには、個人情報の不当な取扱いおよびそれに起因する不利益を防止することが目的であり、その意味において、プライバシー権というより「個人情報の保護を求める権利」と呼ぶことが適切ではないかとする指摘があります(曽我部真裕「自己情報コントロール権は基本権か?」(憲法研究3号(2018年)71頁))。[↩]
- EUにおけるAI規則案(Artificial Intelligence Act案(2023年6月14日欧州議会承認版))では、限定リスクAIシステムであるチャットボットなどを利用する場合には、当該AI利用を明確にすることが求められています(52条)。[↩]
- シンガポール個人データ保護委員会“MODEL ARTIFICIAL INTELLIGENCE GOVERNANCE FRAMEWORK SECOND EDITION”31頁等参照。[↩]

渡邊 満久
AsiaWise Digital Consulting & Advocacy株式会社 取締役
AsiaWise法律事務所 パートナー弁護士
2013年都内法律事務所で業務開始し、主に企業の紛争解決や裁判業務、倒産・M&A・労働等をはじめとする企業法務全般を取り扱う。2018年頃から情報法分野を取り扱うようになるが、当時の弁護士の業務形態・サポート態様での企業へのデータ利活用推進支援に限界を感じ、2019年AsiaWise法律事務所に加入。以降は個人データに限らずデータ全般を利用したビジネス・プロジェクト組成、AI利用に係る法的問題点の解決、クロスボーダーでのデータ利活用等について、課題解決に取り組む。2021年AsiaWise Digital Consulting & Advocacy設立に尽力。

田中 陽介
AsiaWise Digital Consulting & Advocacy株式会社 取締役
2006年外資系企業知財部で勤務開始し、主に通信・エレクトロニクス分野の特許を取り扱う。2010年より東南アジア・南アジアを拠点として多国籍企業のアジア新興国での知財権利化、権利行使に加え、現地スタートアップ企業の知財面を支援。2019年AsiaWise Groupに加入。クロスボーダーでのデータ利活用に加え、通信関連規制、AIやOSSの利用など、技術と法律の両面からの理解が必要なさまざまなプロジェクトにおいて課題解決に取り組む。

西尾 暢之
AsiaWise法律事務所 弁護士
2017年都内の大手税理士法人で勤務開始し、2019年から都内法律事務所にて勤務。国際税務、税務紛争、M&A、海外法令調査などの業務に加え、リーガルファンクションコンサルティングといった法務部のDXに関するコンサルティング業務の経験を有する。2021年AsiaWise法律事務所に加入。現在は主にDXプロジェクトにおけるデータ・情報利活用支援を行う。