はじめに
本連載は、『紛争解決のためのシステム開発法務―AI、アジャイル、パッケージ等にも対応』(法律文化社)(以下、「本書」という)の刊行と、出版記念セミナーの開催を踏まえ、本書をもとにわかりやすく「失敗プロジェクト回避」のためのポイントを説明するものである。
連載第3弾(最終回)として、今回は、AIを利用したシステムの開発やアジャイル型でのプロジェクトを進めるうえでの重要な問題を検討する。
AIを利用したシステムの開発における「失敗回避」ポイント
一口に「AI」と言っても、最近注目されている機械学習型(ML型)のAIと、人間がルールを事前に定め、そのルールどおりに動くルールベースのAIが存在する。以下で、このML型、ルールベースそれぞれについて検討しよう。
ML型(機械学習型)AIの場合
ML型システム開発契約の「失敗回避」の主なポイントは、以下の3点である(詳細は本書を参照いただきたい)。
・ システム開発の「目的」(経営戦略の実現)と、「手段」の優先順位をはき違えない。
・ 質の高いAIを利用したシステムとするためのAIの組み込み方・UI/UXを検討する。
・ 「AIに精度の“保証”は難しい」ということを理解する。
以下、それぞれについて見ていこう。
(1) 経営戦略やシステム開発の「目的」
「AIを利用したシステム」の開発の目的やその位置づけは、あくまでも特定の経営戦略を実現するためのIT戦略の中で決定されるはずである。最も重要なのは「どうすればその目的(経営戦略)を実現できるか」であり、AIやMLは、その目的(経営戦略)を実現するための単なる「手段」に過ぎない。
たとえば、当初はML型のAIの利用が当該目的の実現にとって有効かと思ったものの、実はルールベースのAIや従来型のシステムの利用の方がより目的に適合するということであれば、ML型にこだわる必要はまったくない。ML型AI「ありき」のプロジェクトは失敗する可能性が極めて高い。
また、同様の観点から、「ユーザはどこまでを自社で行い、どこをベンダに委託するか」という区分も行うべきである。何も考えずにベンダに「丸投げ」をしたのでは、ノウハウは自社に蓄積しない。
さらに、プロジェクトが「失敗」したか「成功」したかの定義も、この「目的」と強く結びついている。たとえば、特にML型AIの経験が乏しいユーザが「ML型AIのノウハウの習得」を目的とした小規模プロジェクトを実施し、実際に期待したノウハウを習得できたなら、(そのML型AIがどこまで実用的かはともかく)そのプロジェクトは「成功」と評価することも可能だろう。
(2) ML型AIの質を確保する工夫
次に重要なのは、データの問題はあるが、質の高いAIを利用したシステムとするために、「AIをシステム全体にどう組み込むか」や「UI/UXをどうするか」といった点である。
ML型AIの「質」は、その学習に用いたデータ、検証用データ、そして利用される際の実データに依存する。たとえば、「綺麗な」データで学習したが、実データは「綺麗」とは限られないとすれば、いかにベンダが頑張っても、実環境においてユーザが期待するような性能は発揮できない。
こうした問題は「データの問題」として議論されることが多いものの、筆者の経験上、「AIをシステム全体にどう組み込むか」という論点とも密接に関連することが多い。つまり、AI(学習済みモデル)はそれ単体で存在し、自律するのではなく、システム(ハード、ソフト)の中に組み込まれて運用され、それを人間が利用するという関係性をもつ。このことは、たとえば、ユーザインタフェース(UI)やユーザエクスペリエンス(UX)を改善することで、問題の解消につながる可能性があるということを意味する。
先に挙げた「実データが学習用データとは異なり“綺麗”ではない」という問題は、もちろん「実データに近いデータで学習する」という解決方法もある。しかし一方で、「実データを“綺麗”にするにはどうすればいいか」という観点で解決方法を考えることもできる。
たとえば、セルフレジで画像を撮影してAIに画像認識させ、金額を算定するシステムがあったとする。このとき、商品が重なり合っていると、正しい金額の算定が困難になる。こうしたことを避けるため、セルフレジの利用者に、よりAIの性能が出やすい撮影をしてもらうようなUI/UXとする―具体的には、①トレイを置く枠を設けることで、自然に撮影位置にセルフレジ利用者がトレイを置くようにする、②商品の重なり合いがないよう、利用者への注意書きを掲示するとともに、重なり合いにより判定ができない場合、画像の重なり合い部分をレジ画面に明示して利用者に改善を依頼するなどが考えられる―など、できるだけ正しい金額が算定できるよう、学習用データに近い画像になるように工夫するというのも、一つの重要な解決方法である。
(3) AIの精度「保証」は難しい
ML型AIの経験が少ないユーザは、ML型AIにこれまでのソフトウェアのように「完成保証」「実データでの精度保証」を求め、ベンダに「精度100%」といった要求をするケースがある。しかし、ML型は、確率的に動く性質から、そのような保証は難しい。
たとえば、ユーザが「実データの精度99.99%を保証せよ」と強く求め、交渉の結果、「検証用データの精度99.99%の保証」で合意したとする。当然、ベンダは合意した精度を目指して学習させることになるが、学習データに適合しすぎて、学習データでの精度は高くなるが、それとは異なる未知のデータ(実データ)には対応できず、的外れな回答を出してしまうとった「過学習」を引き起こすなど、むしろ「実データの精度が落ちてしまう」という本末転倒の事態を招く可能性がある。
一方で、「保証ができない」ことは、決して「精度向上を目指す意味がない」ということではない。たとえば人、ソフトウェア(ハード、ソフト)とAIをよりよく組み合わせたうえで、AIの強みを活かした精度向上を目指すなど、AI以外の部分の工夫を含む、「システム全体」での精度向上を考えるべきである。
ルールベースAIの場合
次に、ルールベースのAI、ここではRPA(Robotic Process Automation)について説明しよう。
これまで、繰り返し作業が発生する場合、「エクセル」という同じアプリの中で完結するなら、マクロを使うことで相当程度複雑なものでも正確に繰り返しをしてもらうことができた。
しかし、繰り返しになるが、マクロは基本的には一つのアプリ内で完結する業務に対応している。つまり、メールアドレスに定型的な注文メールが配信され、そのデータに基づき宛名ラベルを印刷するという作業があったとして、「メール受信→内容を宛名ラベル作成ソフトに転記→印刷」というアプリをまたいだ流れは、マクロでの解決は容易ではなかった。
RPAはこのような繰り返し業務を、アプリをまたいでも自動化することができる。AIではあるもののML型と異なり、たとえば「メールの●部分を宛名ラベルの●部分に転記する」といったルールに基づいて働くので、確率論ではない。よって、その入力データが予定どおりである限り、ヒューマンエラーなく動く。
ただし、RPAが適応するのはこうした定型的な繰り返し業務の部分に限られ、それ以外の非定型的業務は対応できない。一方で、多くの業務は、多かれ少なかれ定型業務と非定型業務の組み合わせである。だからこそ、RPAの導入には、
「今どのような業務を行っており、定型業務がどのくらい多いのか。それを切り出してRPAに処理させる場合、今のビジネスプロセスのままで進めるのか、それとも、ビジネスプロセスそのものを変革すべきか」
※ ビジネスプロセスの変革の例:商品の発注対応について、現在は発注のメールの受信の都度、ラベルの印刷や発送などの対応をしていたが、今後は1日分の発注分のラベル印刷をRPAを用いて夜に処理させ、翌朝担当者が出勤後、ラベルを貼って発送するという流れにする など
を考えるべきである。
また、入力データが本当に「予定(ルール)どおりか」も重要だ。人間であれば、入力データにミスがあり、住所欄に氏名が、氏名欄に住所が書かれていても、そのミスを正しく認識して正しく転記できる。しかし、RPAは、基本的には「融通が効かない」(入力ミスはミスのまま変更・修正されない)と理解しなければならない。
このとき、入力データに特記事項がある場合など、「例外的なもの」については、事前に対応を検討しておかなければならない。
上記の宛名ラベルの例であれば、注文欄の特記事項欄に何らかの記載があれば、すべて人間が処理するというのも一つの方法である。また、特記事項欄に単に「なし」との記載があるのみの場合は、なおRPAに処理させることでもよい。ただし、「特になし」「特記事項なし」など、同じ趣旨でも表記揺れが生じてしまう場合、RPAでは設定なしには対応できないので、こうした可能性についても検討しておく必要がある(このような場合の対応策としては、むしろ、デフォルトの入力フォームでは「特記事項なし」のボタンが押されている(特記事項は記入できない)設定とし、特記事項がある場合のみ「特記事項なし」のボタンをクリックして設定を解除し、そこで初めて特記事項を記載できるようにするなど、RPAでの処理率を高める工夫を行うなどとした方がよいかもしれない)。
アジャイル型システム開発の「失敗回避」ポイント
アジャイル型のシステム開発は、流動性があり、常に最新の状況への対応が必要なシステム開発に有効である。
ここで、アジャイル型のシステム開発と、比較対象とされやすいウォーターフォール方式との違い(下記図表1も参照)を「A・B・C・D・Eの五つの機能があるソフトウェアの開発」を例に紹介しておこう。
ウォーターフォール方式では、計画段階においてまず「A・B・C・D・Eの5機能を作る」と確定し、5機能の仕様を決め、そして実際に5機能を開発するという流れをたどる。しかし、開発が済んだ頃には既にビジネスが変化していて「B」の機能が不要になってしまっていたり、「C」の機能の仕様が、当初想定したものとは異なるものが必要となっているというおそれが生じうる。
一方、アジャイル型開発では、まずは大きくA・B・C・D・Eの機能について、今後開発の可能性がある機能だという点について「識別」はするが、必ずしも5機能が開発当初に「固定」されるわけではない。たとえば、当初はA→B→C→D→Eが開発優先順位だったとして、まず「A」の仕様を固めて開発してみたところ、実は新たな機能「F」こそが喫緊の課題であり、「B」は不要になっていたとする。その場合、アジャイル型では、次は当初考えていた「B」ではなく、その時点で優先度が高い「F」機能の仕様確定と開発に移るのである。また、次の「C」機能が開発された後になって、その仕様を大幅に変更すべきとなった場合で、「C」の仕様変更に伴い「D」機能は不要となれば、D機能の作業の代わりに次はC機能の仕様変更対応をすることもありえるのである。こうして、最終的には「A・F・C(仕様変更版)・E」という4機能が、ユーザの求める仕様で完成することになる。これは、不要な「B」「D」と、ユーザの求めない仕様の「C」が完成し、喫緊の課題である「F」がない「A・B・C(仕様変更前)・D・E」の5機能が納品されるウォーターフォール型より格段に優れているといえる。
図表1 一般的なウォーターフォール方式とアジャイル型の工程比較
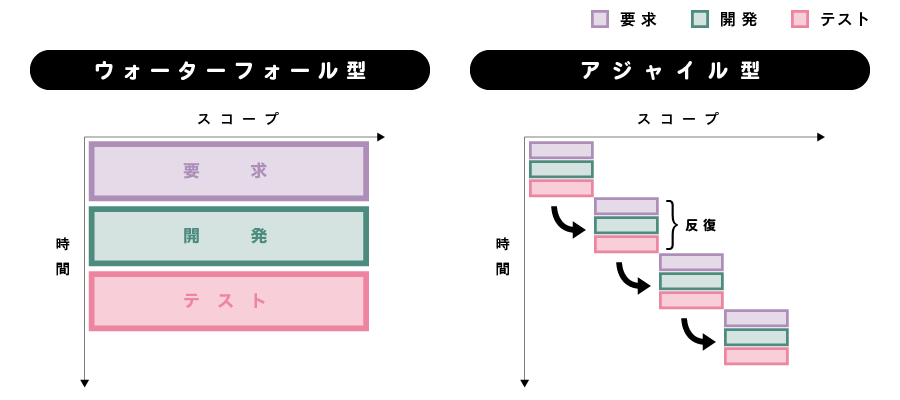
出典:独立行政法人情報処理推進機構ソフトウェア・エンジニアリング・センター「非ウォーターフォール型開発WG活動報告書」(平成23(2011)年3月31日)46頁
ただし、アジャイル型は、「プロジェクト開始後の優先順位変更が一定程度可能である」ということは言えても、決して
- 要件仕様を出したり、決めたりする必要はない。
- 仕様変更は、いつでも、自由に可能である。
ということではない点については、留意しなければならない(なお、筆者が委員を務めた独立行政法人情報処理推進機構社会基盤センターによる「アジャイル開発版「情報システム・モデル取引・契約書」」では、こうした「アジャイル型開発に関する誤解」を解くべく解説を加えている。ご参照いただければ幸いである)。
パッケージ開発契約の「失敗回避」ポイント
最後に、パッケージ開発契約について説明しよう。
パッケージ開発については「既製服」をイメージしていただくとわかりやすい。たとえば、自分が欲しい服がそのラインナップにあれば、それを購入するだけですぐに使えるし、比較的費用も安い。しかし、その既製服が自分の望むものと異なる場合にはどうしたらいいだろうか。
もちろん、「ボタンだけが気にいらない」など、比較的修正が小幅にとどまるのであれば、既製服をベースに変更しても意味はある。しかし、「着物を買って背広に仕立て直す」というレベルのものであれば、そもそも着物を買わず、布から背広を作った方がずっと早い。
もちろん、費用と納期を度外視するなど、大変な努力によって、大元のパッケージを大幅に変更することは完全には「不可能」とはいえないかもしれない。しかし、多くの場合は、パッケージを使わず、ゼロから作り上げる開発(スクラッチ開発)の方が費用も納期もユーザに望ましいものになるだろうし、また、仮にパッケージを使うのであれば、変更は大幅に抑え、業務を変えた方が費用も納期も望ましいものになるだろう。場合によっては、そもそもそのような変更がおよそ不可能だ、ということもありうる。
このように、パッケージ開発を採用する場合には、業務の方をパッケージに合わせたものに変更すべき場合が多くなる。ただし、それは、これまでの「自社の強みを支えてきた業務上の素晴らしい工夫」とか「現場の人が温めてきた、次のシステムにどうしても入れてほしい機能」等を(そのパッケージに多少の変更を加える場合には「すべて」ではないのだろうが、少なくとも一部は)諦めることを意味する。
なお、「“最小限”の変更はする」と決めた場合にどうなるか。おそらく、各部門から「自部門の求める変更こそ“最小限”の変更だ」と、変更要望が殺到するだろう。パッケージを一切変更せずにパラメーター調整程度で導入したほうが、まだ導入時の苦労は平等かもしれない。
この時に重要な役割を果たすのは、やはりユーザの経営陣である。Ⅱ1.(1)で触れたことにも重なるが、そもそも、経営陣は経営戦略と、それを反映したIT戦略を持っている。だからこそ、彼らはそのIT戦略上、どのようなシステムを開発するか、パッケージとするのか、パッケージにするなら変更をしないのか、それとも最低限の変更だけにとどめるか等を決めなければならない。
「パッケージにする」と決めた場合には、(上記のように「大幅に変更する」という極めて不合理な判断をする場合はともかく)大きく現在の自社の業務を変更することになり、それによる現場の反発は強いことが予想される。しかし、その決断が自社の経営戦略・IT戦略に適合するのであれば、経営陣として覚悟を決め、反発するユーザ現場に対して、その必要性を説明し、業務改革を完遂しなければならないことは、言うまでもない。
* *
以上、3回にわたり、さまざまな場面におけるシステム開発の「失敗回避」のポイントを紹介してきた。
より詳細な解説は、本書に掲載されている。興味のある本連載の読者がおられたら、ぜひ本書やセミナーをご参照・受講いただきたい。
本連載、そして、本書とセミナーが、システム開発に携わる企業の担当者のお役に立てれば幸いである。
→この連載を「まとめて読む」

松尾 剛行
桃尾・松尾・難波法律事務所 パートナー弁護士・ニューヨーク州弁護士
プロジェクトマネージャ・情報セキュリティスペシャリスト・ITストラテジスト
2006年東京大学法学部卒業。2007年弁護士登録、桃尾・松尾・難波法律事務所入所。2013年Harvard Law School卒業(LL.M.)。2015年北京大学法学院卒業(法学修士)、2020年北京大学法学院卒業(博士(法学))。独立行政法人 情報処理推進機構(IPA)社会基盤センター社会実装推進委員会モデル取引・契約書見直し検討部会DX対応モデル契約見直し検討WG委員や一般財団法人 ソフトウェア情報センター(SOFTIC)の「システム開発紛争判例研究会」「AIに関する法的問題検討委員会」「OSS(オープンソースソフトウェア)委員会」各委員。著作『紛争解決のためのシステム開発法務―AI、アジャイル、パッケージ等にも対応』(法律文化社、2022)、『裁判例から考えるシステム開発紛争の法律実務』(共著)(商事法務、2017)ほか多数。
この記事に関連するセミナー
-
セミナー
- 受付終了
-
申込受付終了
好評につき再掲載【出版記念】紛争解決のためのシステム開発法務 -AI・アジャイル・パッケージ開発等のトラブル対応-「基礎編」
桃尾・松尾・難波法律事務所 パートナー弁護士 松尾剛行 氏
-
セミナー
- 受付終了
-
申込受付終了
ユーザの観点からみた紛争解決のためのシステム開発法務 -松尾剛行=西村友海『紛争解決のためのシステム開発法務』を使いこなして契約レビュー、プロジェクト支…
桃尾・松尾・難波法律事務所 パートナー弁護士 松尾剛行 氏
-
セミナー
- 受付終了
-
申込受付終了
ベンダの観点からみた紛争解決のためのシステム開発法務 -松尾剛行=西村友海『紛争解決のためのシステム開発法務』を使いこなして契約レビュー、プロジェクト支…
桃尾・松尾・難波法律事務所 パートナー弁護士 松尾剛行 氏