はじめに
2025年2月、経済産業省は「AIの利用・開発に関する契約チェックリスト 」( 以下、「チェックリスト」という)を公表した。近年、ChatGPTなどの生成AIの普及により、AIの利活用に関する契約の重要性が高まっていることを受け、実務で使いやすい形の指針として策定されたものである。
チェックリストは、AI利活用の実務経験は問わず、幅広い読者を念頭に置いており、以下の利用場面を想定している。
・ 社内法務部・顧問弁護士等が契約条項を具体的に検討する場面
・ ビジネス部門担当者等が契約についての初期的な検討を行う場面
図表1 チェックリストの主な想定読者と利用場面

出典:チェックリスト3頁。
本稿では、筆者自身が生成AIを用いたツール開発・検証事業に携わった実務経験も踏まえ、近年、急速に普及している大規模言語モデル(LLM)を用いた生成AI(テキスト生成、要約、翻訳、議事録作成、チャットボット等に活用される)も念頭に置きつつ、チェックリストの要点を解説する。
なお、チェックリスト自体は生成AIのみならず、いわゆる識別系AI(与えられた情報から予測・分類を行うAI)も含むAI全般を対象としている。
チェックリストの前提部分(AIのシステム、当事者、ユースケース、契約の類型)
チェックリストでは、契約の具体的な検討の前提として、①対象となるAIシステムの構成や、②関係当事者、③想定されるユースケース・契約類型について整理がなされている。
以下、大規模言語モデル(LLM)を用いた生成AIを念頭に置きつつ、具体例を示す。
AIシステム
チェックリストでは、識別系・生成系を問わず共通するAIシステムの構成として、
① インプットとアウトプット
② 導入プロセス
③ 技術的調整
の三段階からなる全体像が以下のとおり示されている。
図表2 AIシステム概要
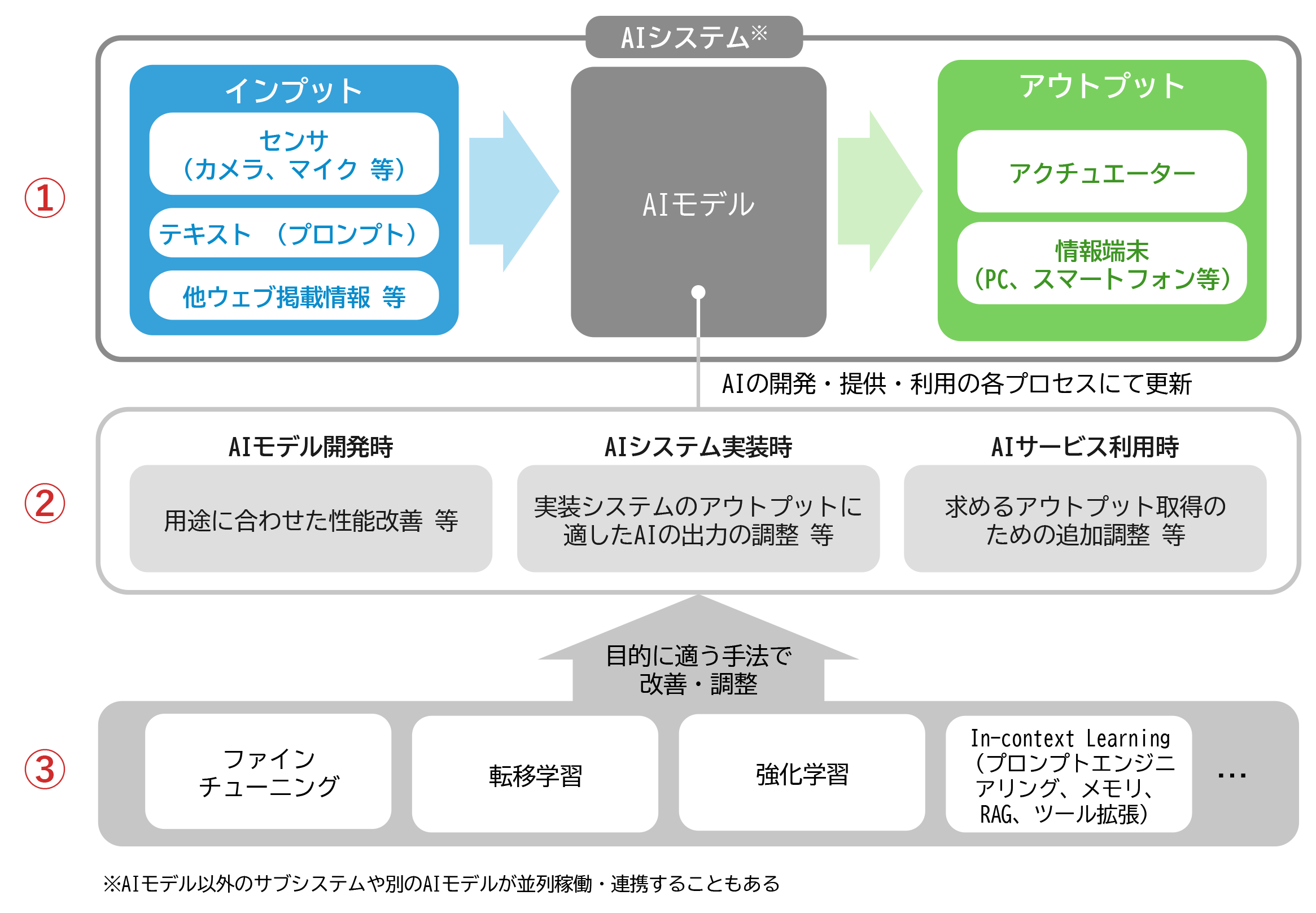
出典:「AI事業者ガイドライン(第1.01版)別添(付属資料)」 6頁
出典:チェックリスト4頁(赤字部分は筆者による)。
筆者の経験上、生成AIを用いた開発において重要なのは、このAIシステムの仕組みの理解に加え、どのモデルを使っているか、どのような手法で処理しているか、プロンプト設計はどうなっているかなど、技術的構成に関する一定の理解が発注者側にも求められるということである。こうした理解が欠けていると、ベンダが採用している手法の妥当性や成果物の性質を把握できず、レビューや判断が形骸化してしまうリスクがある。その結果、開発の方向性を誤ったまま検討が進行したり、成果物の評価が困難になったりするなどの問題に発展しかねない。しかし、現実的な問題として、AIの技術的事項は極めて専門性が高いため、たとえば発注者側で、AIの技術面に詳しいアドバイザーを確保しておくといった手法も重要となる。
当事者
チェックリストでは、契約上の立場として、以下のとおり「AI開発者」「AI提供者」「AI利用者」の三つの当事者が登場する。
図表3 各当事者の定義

出典:「AI事業者ガイドライン(第1.1版)」5頁
出典:チェックリスト5頁。
図表3でそれぞれの定義が示されているが、実務において、具体的にどのような企業が該当するのかはチェックリストに明記されていない。各当事者の具体例を補足すると以下の通りとなる。
AI開発者:大規模言語モデル(LLM)そのものを自ら設計・学習して構築している企業が該当し、GPT-4などの基盤モデルを開発しているOpenAIが典型例。
AI提供者:AIモデル自体を開発していないが、モデルをサービスとして組み込み、企業に実装・運用可能な形で提供する事業者。たとえば、カスタマーサポート業務に生成AIチャットボットを導入できるよう、企業にAPI連携型のサービス※を提供するAI事業者。
AI利用者:提供された生成AIを業務などに利用する企業や個人。
※ 「API連携型のサービス」:生成AIを用いたシステムはどうやって開発されているか?
「API連携型のサービス」とは、たとえばOpenAIが開発したGPTのようなLLM(大規模言語モデル)を、自社で設計したチャット画面や操作機能と組み合わせ、業務に必要な情報のやりとりを自動化できるようにした仕組みを指す。ユーザにAIツールを開発・提供する事業者の多くはこの仕組みを利用している。たとえば、チャットボットの中で生成AIを使いたい部分(回答生成機能)について、OpenAIのLLMを利用してチャットボットの中に組み込む、というイメージである。
ユースケースと契約類型
チェックリストでは、AIを活用する契約類型として、以下の三つのパターンが示されている。
それぞれの類型で契約リスクの所在や交渉のポイントが異なるため、自社のケースがどの類型に該当するかを正しく把握することが重要となる。
類型1:汎用的AIサービス利用型

出典:チェックリスト7頁。
OpenAIのChatGPTやGoogleのGeminiなど、既に提供されている生成AIを、そのまま業務で利用するケース。たとえば、小売業の企業が、OpenAIの「ChatGPT」に購買履歴(年齢、購入商品、時期など)をプロンプトとして入力し、消費者の嗜好傾向を分析させるケースが該当する。
ユーザはウェブ画面等を通じてサービスを利用するが、契約は提供事業者が定めた「利用規約(約款)」に同意する形で成立することが想定され、個別に契約交渉を行う余地は少ないと考えられる。
類型2:カスタマイズ型
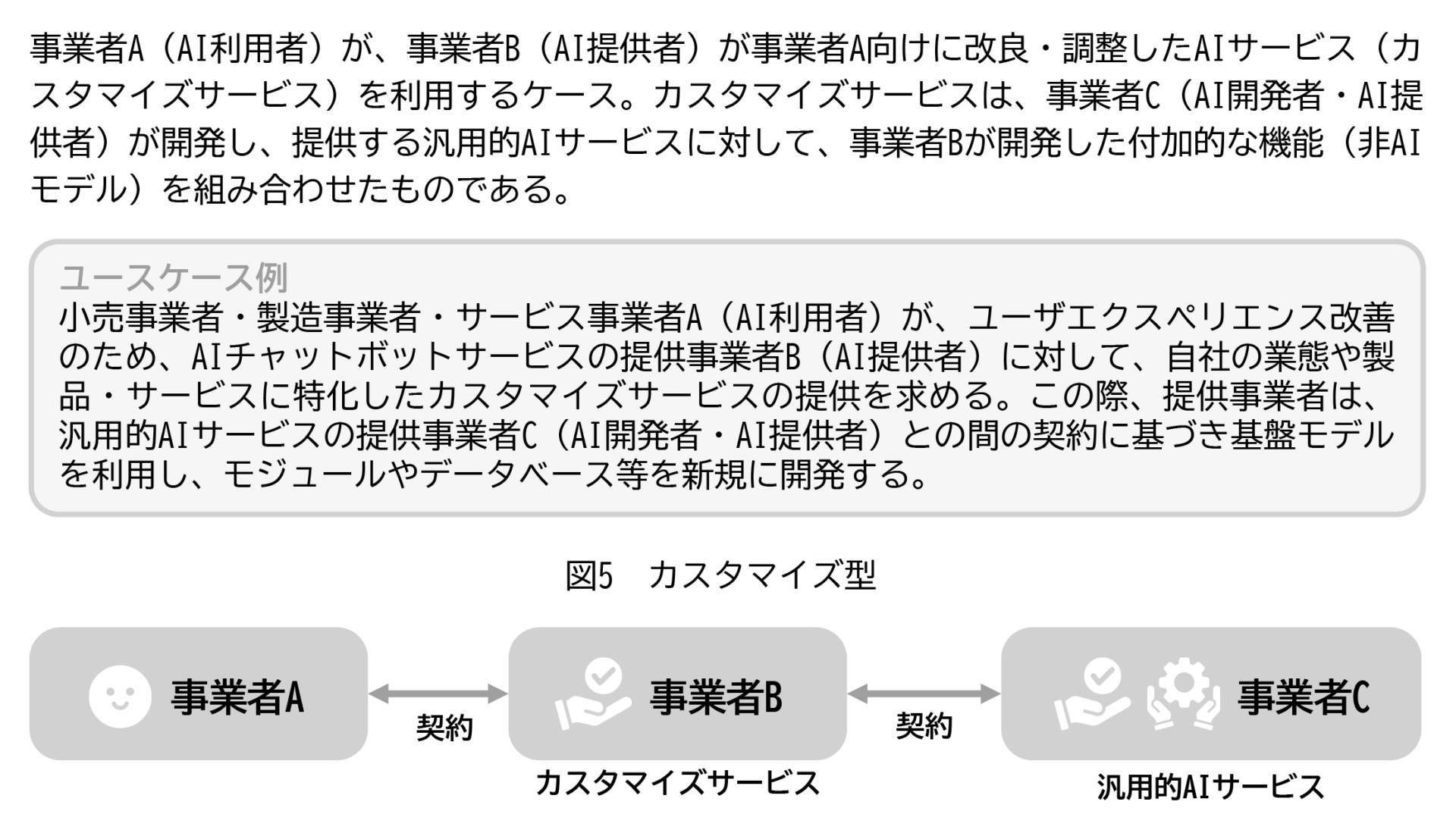
出典:チェックリスト7頁。
自社の業務に合わせてチャット画面やデータ連携機能を加えたツールを、外部ベンダに構築してもらうケース。この場合、ベンダが外部のLLMを利用しつつ、自社のニーズに応じた機能や画面を追加する。たとえば、小売業の企業が、チャットボットサービスを構築するにあたり、商品説明データや在庫情報、販売実績などと連携させたシステムを開発ベンダに依頼し、当該ベンダがOpenAIのLLMを利用して、チャットボットを開発するケースが該当する。
契約内容の交渉や設計が可能であり、実務で多く見られる類型であると考えられる。
類型3:AI開発委託型
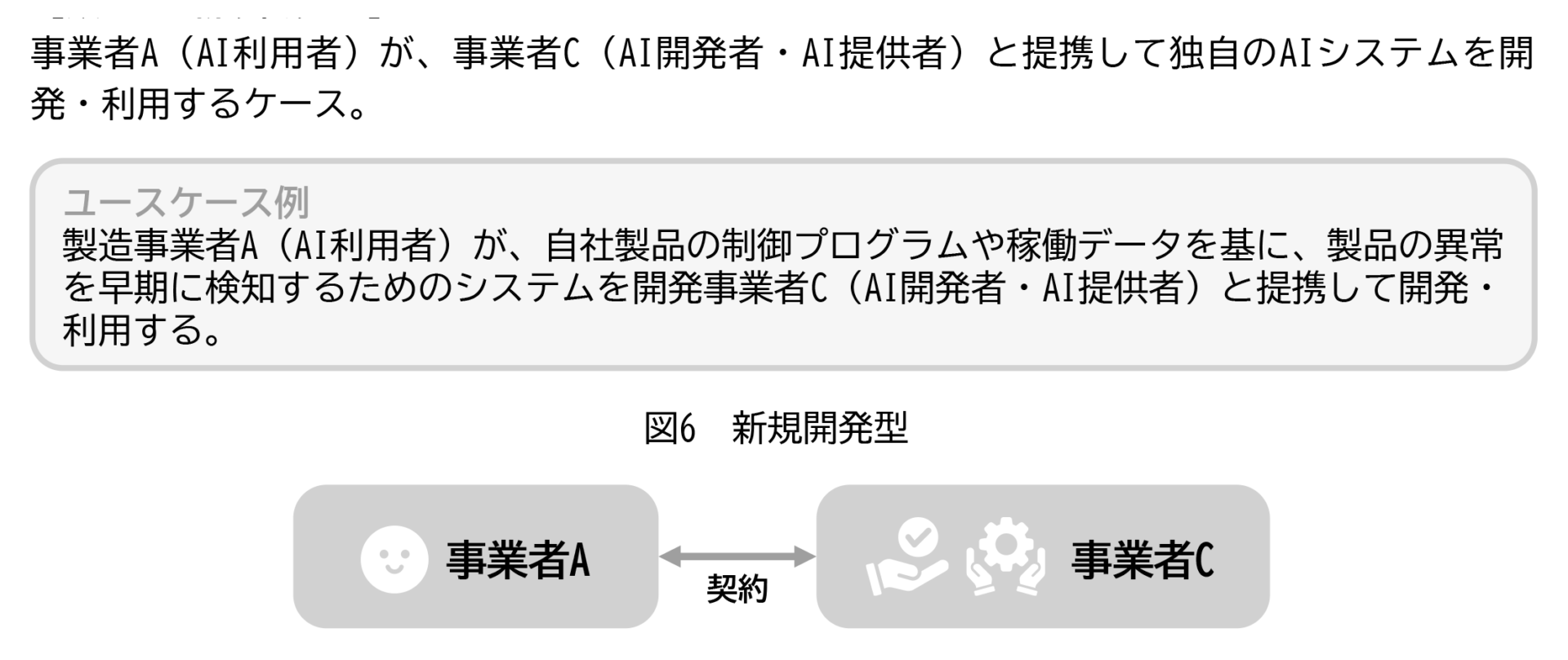
出典:チェックリスト8頁。
企業が外部のAI開発者と提携し、自社専用のAIモデルやアルゴリズムをゼロから設計・開発するケース。たとえば、製造業の企業が、設備の稼働データを基に、異常を早期に検知するAIモデルを開発会社に委託し、異常検知アルゴリズムそのものを一から構築してもらうケースが該当する(生成AIではなく、識別系AI)。
ポイント:大規模言語モデル(LLM)を用いた生成AIで想定される類型
LLMの構築には莫大な計算資源と専門知識が必要なため、生成AIを利用する契約では、類型3に該当することはあまり想定されず、実務上のほとんどが類型1または2に該当すると考えられる。
また上記の通り、類型1では交渉の余地は少ないと考えられるため、実務的には類型2において、チェックリストがもっとも多く利用されると想定される。
チェックリスト
チェックリストの構成
チェックリストは、具体的な契約条文のひな型を示すものではなく、契約書を確認する際に、現行条項が十分か、また必要な条項が漏れていないかを確認するための整理指針として活用されるものである。
全体構成は以下の図表4のとおり、AIの利用にあたって中心となる「インプット(A)」と「アウトプット(B)」、それぞれに関する論点を軸に設計されている。
図表4 チェックリストの対象となる条項
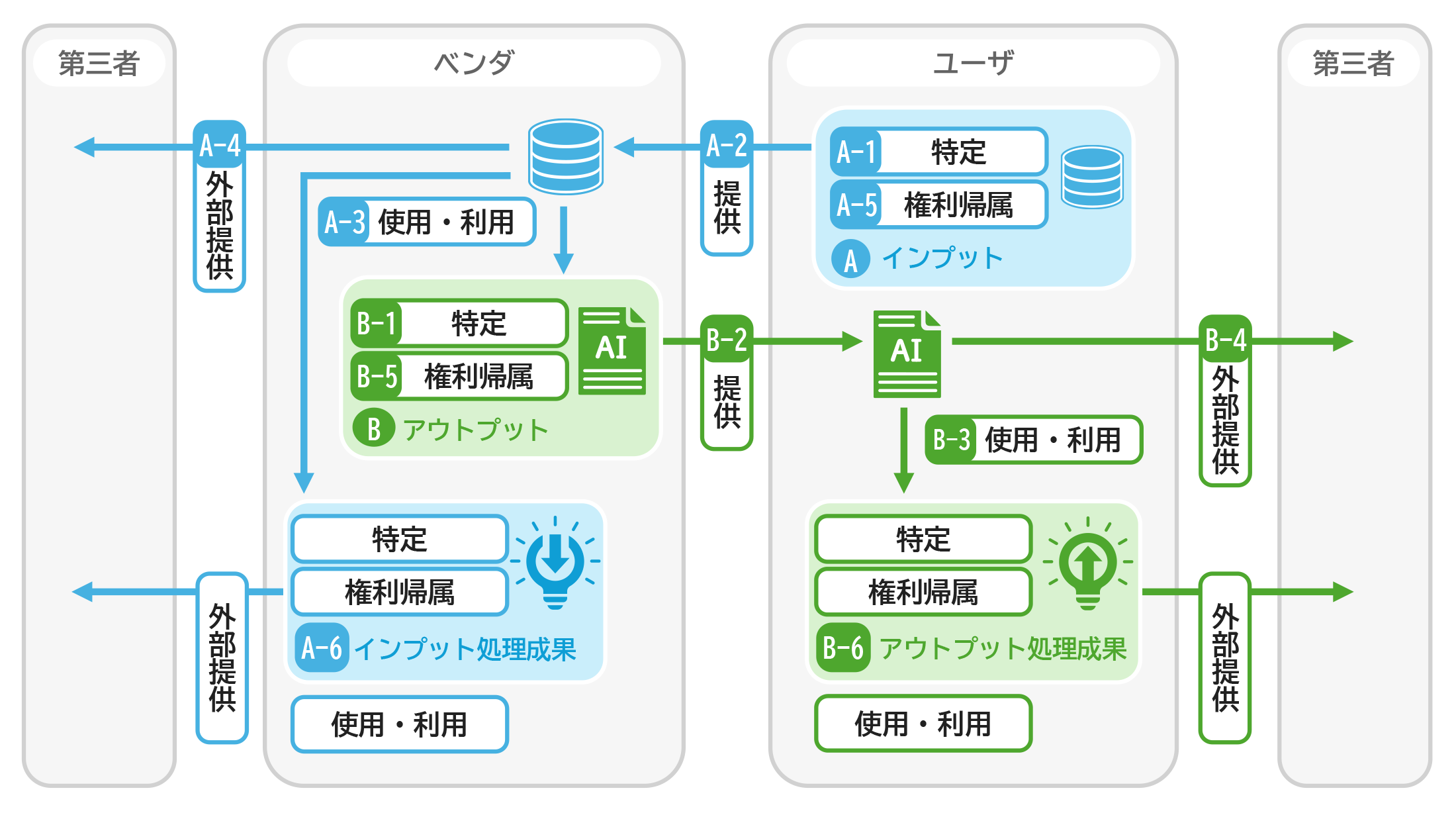
出典:チェックリスト11頁。
・ インプット(A):プロンプト、学習用の生データ等
・ アウトプット(B):分析結果・コンテンツ等のAI生成物、AIシステム等の成果物等
・ インプット処理成果(A-6):学習用データ、中間生成物、派生的知的財産等
・ アウトプット処理成果(B-6):AI関連サービスが出力するコンテンツを自ら加工したもの等
そして、インプットとアウトプットは、以下の六つの観点に分類して整理されている。
① 特定(定義・対象の明確化)
② ベンダへの提供(提供義務・条件など)
③ 使用・利用(誰がどのように使うか)
④ 外部提供(第三者への開示・共有)
⑤ 権利帰属(知的財産権の所在)
⑥ 処理成果(中間・派生成果物の取扱い)
チェックリスト本文
体系的な理解のため、チェックポイントを整理した表は以下の通りである。
図表5 インプット(プロンプト、学習用の生データ等)
| 観点 | チェックポイント要約 | 対応ポイント |
| 特定 (A-1) |
契約上保護すべき情報がインプットの定義に含まれているか、定義に曖昧さがないかを確認し、ユーザの利用目的に照らして妥当かを検討。 |
定義に含まれない情報はベンダが自由に使える可能性があるため、範囲の明確化が必要。 |
| ベンダへの提供 (A-2) |
■提供義務・条件(A-2-1) ■保証・情報提供(A-2-2) |
提供条件が不明確な場合、他社との契約違反や法令違反のリスクがあるため、契約上での明示が重要。 |
| 使用・利用 (A-3) |
■利用目的(A-3-1) ■利用条件(A-3-2) ■管理・セキュリティ(A-3-3) ■保持期間・消去(A-3-4) |
目的外利用を許容するかは慎重に判断すべき。管理体制が不十分な場合は提供自体を再検討する必要がある。 |
| 外部提供 (A-4) |
■ユーザへの提供(A-4-1) ■第三者提供(A-4-2) |
第三者提供禁止義務や秘密保持条項に基づき、提供条件を具体的に定めておかないと情報流出のリスクがある。 |
| 権利帰属 (A-5) |
ベンダがインプットの権利を取得するか確認。取得する場合、その条件(対象、対価、ライセンスなど)。ユーザの利用目的に照らして許容性を評価。 |
一般にはユーザに帰属するのが原則。例外的にベンダに帰属させる場合は、その条件を明示することが不可欠。 |
| インプット処理成果 (A-6) |
処理成果の定義に疑義がないか。ベンダの利用条件、第三者提供の有無・条件、権利の帰属について検討。 |
成果物はベンダの技術が含まれることが多いため、自動提供されるとは限らず、定義と帰属の明確化が必要。 |
※ チェックポイントは多数あるため、筆者において、要点のみを記載している。実際に契約をチェックする際は、チェックリストを直接参照されたい。
※ 「対応ポイント」は、チェックリスト上の事実上とりうる対応・備考欄から筆者が要点を追記したものである。
図表6 アウトプット(分析結果・コンテンツ等のAI生成物、AIシステム等の成果物等)
| 観点 | チェックポイント要約 | 対応ポイント |
| 特定 (B-1) |
■定義(B-1-1) |
契約上のアウトプットの範囲が曖昧だと、利用目的外の争いが生じやすい。定義の具体性が重要。 |
| ユーザへの提供 (B-2) |
■完成義務(B-2-1) ■提供義務・条件(B-2-2) ■保証・情報提供(B-2-3) |
請負型契約では完成義務が重要。提供条件や品質・精度の定義が曖昧だとトラブルの元になる。 |
| 使用・利用 (B-3) |
■利用目的(B-3-1) ■利用条件(B-3-2) ■管理・セキュリティ・消去(B-3-3) |
想定外の転用や漏洩を防ぐには、利用目的と禁止事項、消去体制の明記が不可欠。 |
| 外部提供 (B-4) |
■第三者提供(B-4-1) |
再配布・開示を前提とする場合は、提供条件や著作表示の要否などの明示が必要。 |
| 権利帰属 (B-5) |
■権利帰属(B-5-1) |
帰属先が不明確だと再利用や移転時に支障をきたす。ライセンス条件と合わせて明示が望ましい。 |
| アウトプット処理成果 (B-6) |
■特定(B-6-1) ■使用・利用(B-6-2) ■外部提供(B-6-3) ■権利帰属(B-6-4) |
ユーザが加工した成果物に関する定義・利用・帰属は、アウトプット本体と分けて整理が必要。 |
※ チェックポイントは多数あるため、筆者において、要点のみを記載している。実際に契約をチェックする際は、チェックリストを直接参照されたい。
※ 「対応ポイント」は、チェックリスト上の事実上とりうる対応・備考欄から筆者が要点を追記したものである。
留意点(実務上のポイント、リスク)
契約上のチェック項目については以上であるが、本チェックリストには、実務上、特に留意すべき点やリスクが解説されている。そのうち、いくつかポイントを絞って以下記載する。
インプットの提供に関する留意点
(1) インプットとアウトプットの取扱い
AIサービスでは、ユーザが提供するインプット(例:社内データや業務情報)に基づいて、アウトプット(例:生成文章や分析結果)が提供されるため、インプットとアウトプットの取扱いは、契約上の核心である。チェックリストでは、以下のようなリスクが指摘されている。
図表7 インプットの提供に関する主なリスク
| リスク | |
| インプット |
知的財産権の移転 |
| 目的外利用 AI関連サービス提供に必要な範囲を超えて利用されるリスク |
|
| アウトプット | 商業利用の制限 業務利用を前提としているのに、契約で商用利用が認められていないというリスク |
| 第三者権利の侵害 アウトプットが他人の著作権等を侵害してしまうリスク |
|
| 品質の問題 アウトプットにバイアスや不正確な回答が発生するリスク |
(2) インプットについてより注意を要する点
さらに注意すべきは、インプットが汎用的なAI学習目的(例:ChatGPT等への入力)に利用される場合である。この場合、以下のリスクが高まる。
図表8 インプットが汎用的AI学習目的に利用される場合の主なリスク
| リスクの概要 | リスクの具体的な内容 |
| 個人情報保護法違反 |
本人同意なく個人データを第三者に提供したとみなされる可能性 |
| 自社の機微情報流出 |
AI関連サービス次第では、第三者からのアクセスやプロンプトを通じて、インプットの内容が漏洩する可能性。特に、不正競争防止法上の営業秘密に該当する情報については、以後要保護性が失われる可能性 |
| 秘密保持義務等違反 |
他社との秘密保持契約に反して情報を入力してしまう可能性 |
| 知的財産権等の権利利益侵害 |
第三者の著作物を無断で入力することにより、著作権(複製権・翻案権等)を侵害する可能性 |
開発型契約の留意点
生成AIを用いたサービスの開発をベンダに委託する場合、その多くは開発型契約に該当し、特にアウトプットの取扱いや成果物の水準に関して注意が必要となる。
(1) 契約の性質決定(準委任か請負かの判断)
開発型の契約に関しては、その契約の性質が、民法上の準委任契約であるか、請負契約であるかが一つの交渉事項とされることがある。
| 準委任契約 (民法656条、643条) |
ベンダは委任事務の遂行を目的とし、善管注意義務(民法644条)を負うに留まる。 |
| 請負契約 (民法632条) |
ベンダは仕事の完成義務(民法632条)および契約不適合責任(民法559条、562条から564条)を負う。 |
委託者としては、一定のクオリティを求め、当該基準に達しない場合にはベンダに責任を問うべく、一般的には請負契約を希望することが多いと考えられる。他方、受託者としては、AIを用いた開発は、やってみないと結果が分からないことが多いという性質上、準委任契約を希望することが多いと考えられる。しかし、いずれにせよ、契約の性質の区分は、あくまでも当事者間で合意がない場合の補充的なルールを定めるにすぎないため、重要なのは、開発型契約が準委任契約か請負契約のどちらに分類されるかを抽象的に議論することではなく、むしろユーザがベンダに対して、成果の内容や水準をどの程度求めるのかを明確にし、その点を交渉、契約の中で明らかにしておくことである。
(2) 生成AIを用いた成果物等に関する実務上のポイント(筆者の経験に基づく)
筆者の経験上、生成AIを活用した開発は、従来のロジックベースの開発に比べ、「やってみないとどんな出力が得られるかわからない」という不確実性が大きい。このため、成果物のイメージや合意内容をあらかじめすり合わせておくことが重要である。
また、生成AIは、端的にいえば入力に対して「もっともらしい語」を確率的に出力する仕組みであり、質問内容を理解して回答を返すわけではない。そのため、見た目には自然でも誤った内容(いわゆるハルシネーション)が避けられず、100%正しい出力を期待することはできない。このような特性を踏まえ、例えば正解データ100件に対し何件正答できるかを基準とするなど、評価方法を事前に定めておくことがトラブル防止につながる。なお、評価にあたっては単なる正解率だけでなく、誤りの重大性や出力がどこまで網羅できているか(カバレッジ)など、複数の観点から総合的に判断することが望ましい。
また、完全自動での運用を前提とするのではなく、人による確認や補正を前提とする「人間中心の運用設計(Human-in-the-loop)」を採用することが、実務上も安全かつ現実的である。もし人による確認なしで100%の正答率を求めるのであれば、ハルシネーションが不可避である以上、生成AIの導入自体を再検討すべきである。
その他留意点
チェックリストには、その他、知的財産の観点からの権利帰属や、個人データの国内外提供に関する個人情報保護法上の留意点(第三者提供や越境移転規制の観点)、クラウド利用を含むAIサービスの安全確保の観点からのセキュリティ対策(例えばSBOM注1)の取得、監査権限の確保、ログ保存義務など)についても整理されている。必要に応じてチェックリストの該当箇所を参照されたい。
おわりに
AIの契約に限った話ではないが、チェックリストにも記載されている重要な観点として、望ましくない条件であっても、そのリスクの発生可能性や影響度を冷静に見極め、事業上許容できる範囲内にあると判断できる場合には、リスクを受容して契約を進めるという選択も合理的であることは理解しておく必要がある。重要なのは、担当者がAIの仕組みを一定程度理解したうえで、どのようなリスクがあり、それがどの程度の蓋然性で発生しうるか、また発生した場合にどの程度の影響があるかを正しく把握することである。
※ なお、本記事は、筆者個人の見解を記載したものであり、デジタル庁の見解ではない。
→この連載を「まとめて読む」
- SBOM(Software Bill of Materials)とは、ソフトウェアを構成するすべての部品(ライブラリやモジュールなど)を一覧にしたリストであり、ソフトウェアの安全性や脆弱性の管理を行ううえで重要とされている。[↩]

上田 知季
弁護士法人御堂筋法律事務所 弁護士
14年立命館大学法学部卒業。17年京都大学法科大学院修了。19年弁護士法人御堂筋法律事務所入所。24年にCornell Tech(Master of Laws〔LL.M.〕 in Law, Technology, and Entrepreneurship)卒業。現在、デジタル庁政策・法務ユニットに法務スペシャリストとして出向し、生成AIを利用した条文案の生成等、デジタル技術を用いて政府内の法制事務のDXを進める検証事業に、現場の担当者として携わっている。
御堂筋法律事務所プロフィールページはこちらから